Zrozumienie pliku robots.txt WordPressa w dużym stopniu pomoże Ci poprawić SEO Twojej witryny. W tym przewodniku dowiesz się, czym jest plik robots.txt, a co najważniejsze, nauczysz się, jak go używać.
Zasadniczo plik robots.txt jest przeznaczony dla robotów, czyli oprogramowania, które np. przeszukuje strony internetowe i indeksuje je pod kątem wyników wyszukiwania.
Umożliwia właścicielom witryn zablokowanie botom wyszukiwarek indeksowania niektórych stron lub treści na ich stronie internetowej. Niewłaściwe użycie pliku robot.txt może zrujnować SEO Twojej witryny.
Wszystko, czego potrzebujesz, aby dowiedzieć się o tym temacie, jest zawarte w tym przewodniku.

Czym jest plik robots.txt w systemie WordPress?
Plik robots.txt, fundamentalna część rozwoju sieci i SEO, służy jako przewodnik dla botów wyszukiwarek, instruując je, które części witryny mogą, a których nie mogą indeksować. Jego początki sięgają początków Internetu, co czyni go kluczowym elementem relacji między witrynami a wyszukiwarkami.
Historia robotów.txt
W połowie lat 90., gdy internet zaczął się rozwijać, potrzeba organizacji i indeksowania treści internetowych stała się oczywista. Wyszukiwarki wdrażały boty, znane również jako crawlery, aby poruszać się po rozległych zasobach informacji online i indeksować je. Jednak nie wszystkie treści witryn internetowych były przeznaczone do publicznego indeksowania, co doprowadziło do stworzenia protokołu robots.txt w 1994 r. Ten prosty plik tekstowy został zaprojektowany, aby zapewnić właścicielom witryn środki komunikacji z tymi botami, kierując ich indeksowaniem i zapewniając, że wrażliwe lub nieistotne strony pozostaną niezindeksowane.
Jak działa plik Robots.txt
W swojej istocie plik robots.txt jest prosty. Umieszczony w katalogu głównym witryny, używa prostej składni, aby instruować boty, których katalogów lub stron unikać. Na przykład wiersz „Disallow: /private” mówi botom, aby pominęły katalog „private” podczas indeksowania. Z kolei „Allow: /public” oznaczałoby, że katalog „public” jest otwarty do indeksowania. Plik może również kierować boty do mapy witryny, co dodatkowo wspomaga proces indeksowania poprzez wyróżnienie struktury witryny.
Ewolucja i najlepsze praktyki
Na przestrzeni lat zastosowanie pliku robots.txt ewoluowało. Podczas gdy jego podstawowy cel pozostał ten sam, podejście do jego implementacji stało się bardziej ulepszone. Nowoczesne najlepsze praktyki sugerują zrównoważone wykorzystanie pliku, zapewniając, że nie ogranicza on nadmiernie botów ani nie pozostawia zbyt wiele otwartego do indeksowania. Celem jest efektywne kierowanie botami przez witrynę, zwiększając SEO witryny, jednocześnie chroniąc wrażliwe obszary przed publicznym widokiem.
Korzyści z tworzenia zoptymalizowanego pliku txt dla robotów
Głównym powodem tworzenia pliku robots.txt jest uniemożliwienie robotom wyszukiwarek indeksowania pewnych treści na Twojej stronie internetowej.
Na przykład nie chcesz, aby użytkownicy mieli dostęp do folderu motywu i administratora, plików wtyczek i stron kategorii Twojej witryny.
Ponadto zoptymalizowany plik robots.txt pomaga zachować to, co jest znane jako limit indeksowania. Limit indeksowania to maksymalna dopuszczalna liczba stron witryny, które boty wyszukiwarek mogą indeksować jednocześnie.
Chcesz mieć pewność, że indeksowane są tylko przydatne strony, w przeciwnym razie Twój limit indeksowania zostanie zmarnowany. Dzięki temu znacznie poprawisz SEO swojej witryny.
Po trzecie, dobrze napisany plik robots.txt może pomóc zminimalizować działania botów wyszukiwarek, w tym złych botów, wokół Twojej witryny. W ten sposób prędkość ładowania Twojej witryny znacznie się poprawi.
Najlepsze praktyki SEO i typowe błędy w pliku Robots.txt
Optymalizacja pliku robots.txt Twojej witryny jest kluczowym krokiem w ulepszaniu strategii SEO. Jednak łatwo wpaść w typowe pułapki, które mogą nieumyślnie zaszkodzić widoczności Twojej witryny w wyszukiwarkach. Tutaj przyjrzymy się podstawowym najlepszym praktykom SEO w zakresie efektywnego korzystania z pliku robots.txt i podkreślimy kilka typowych błędów, których należy unikać.
Najlepsze praktyki dla pliku Robots.txt
- Bądź konkretny: Używaj precyzyjnych ścieżek w swoich dyrektywach. Na przykład, jeśli chcesz zablokować konkretny katalog, użyj „Disallow: /example-directory/” zamiast szerokiej reguły, która może nieumyślnie zablokować więcej treści niż zamierzano.
- Używaj ostrożnie: Pamiętaj, że plik robots.txt jest potężnym narzędziem. Mały błąd może uniemożliwić wyszukiwarkom dostęp do ważnych treści. Zawsze dokładnie sprawdzaj swoje zasady.
- Regularne aktualizacje: Wraz z rozwojem witryny powinien ewoluować plik robots.txt. Regularnie go przeglądaj i aktualizuj, aby odzwierciedlał nową treść lub zmiany strukturalne w witrynie.
- Utrzymaj dostępność: Umieść plik robots.txt w katalogu głównym swojej witryny. Dzięki temu będzie on łatwo dostępny dla robotów wyszukiwarek.
- Unikaj blokowania plików CSS i JS: Wyszukiwarki takie jak Google muszą mieć dostęp do tych plików, aby poprawnie renderować Twoje strony. Ich blokowanie może negatywnie wpłynąć na renderowanie i indeksowanie Twojej witryny.
- Uwzględnienie mapy witryny: Dołącz ścieżkę do swojej mapy witryny w pliku robots.txt. Pomaga to wyszukiwarkom odkrywać i indeksować Twoją zawartość bardziej efektywnie.
Typowe błędy, których należy unikać
- Nadmierne używanie Disallow: Nadmierne ograniczanie dostępu do wyszukiwarki może prowadzić do niezindeksowanych stron i utraty możliwości SEO. Blokuj tylko treści, które naprawdę muszą być ukryte przed wyszukiwarkami.
- Blokowanie ważnych treści: upewnij się, że nie blokujesz przypadkowo dostępu do stron lub zasobów, które mają wpływ na wartość SEO Twojej witryny, takich jak strony produktów lub ważne artykuły.
- Błędy składniowe: Nawet małe literówki mogą mieć poważne konsekwencje. Niewłaściwie umieszczony „/” lub „*” może zmienić zakres reguły, więc sprawdź składnię dwukrotnie.
- Zaniedbanie pliku: Nieaktualny plik robots.txt może być tak samo szkodliwy, jak jego brak. Upewnij się, że odzwierciedla on obecną strukturę witryny i strategię treści.
- Używanie pliku Robots.txt dla prywatności: Jeśli próbujesz zachować poufne informacje w tajemnicy, plik Robots.txt nie jest rozwiązaniem. Zablokowane adresy URL mogą nadal pojawiać się w wynikach wyszukiwania bez treści. Użyj ochrony hasłem lub tagów noindex dla treści prywatnych.
Jak utworzyć plik Robots.txt w WordPressie
Tworzenie pliku robots.txt w WordPressie to prosty proces. Możesz to zrobić ręcznie lub użyć wtyczek WordPressa . W tym przykładzie będziemy używać wtyczki Yoast SEO.
Korzystanie z wtyczki Yoast SEO
Wtyczka Yoast SEO może utworzyć plik robot.txt dla WordPressa w locie. Oczywiście, robi o wiele więcej, jeśli chodzi o SEO dla WordPressa.
Przede wszystkim zainstaluj i aktywuj wtyczkę, jeśli tego jeszcze nie zrobiłeś.
Po uruchomieniu Yoast na swojej stronie internetowej przejdź do SEO >> Narzędzia. Następnie kliknij odnośnik
Edytor plików w panelu Yoast.
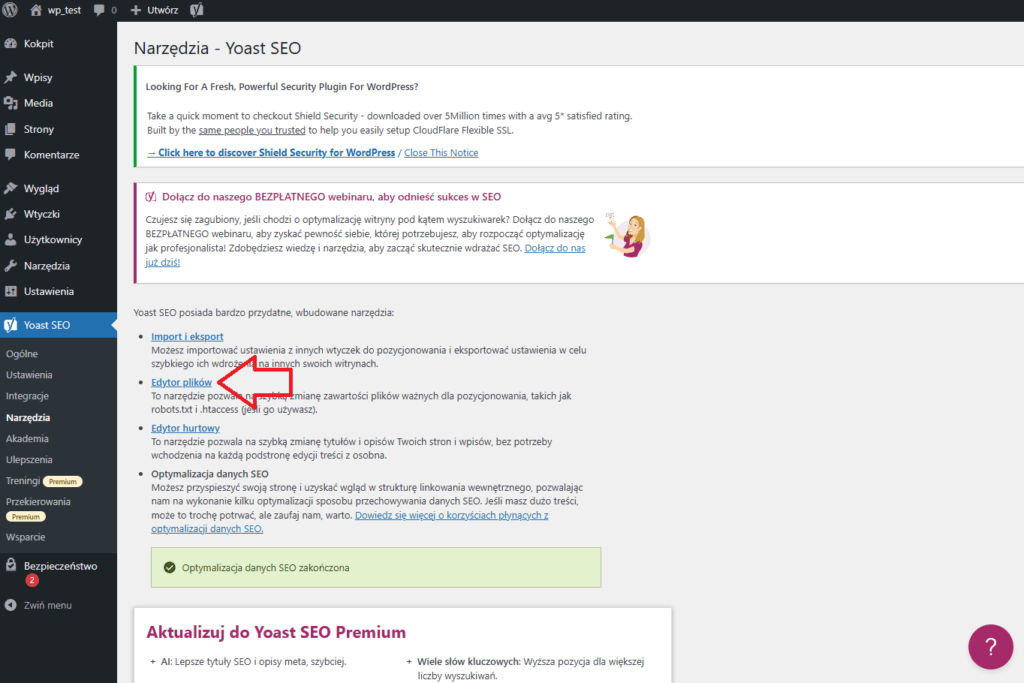
Przeniesie Cię to na stronę, na której możesz utworzyć plik robots.txt. Kliknij przycisk
Utwórz. Spowoduje to przejście do edytora, w którym możesz dodawać i edytować reguły w pliku robots.txt w systemie WordPress.
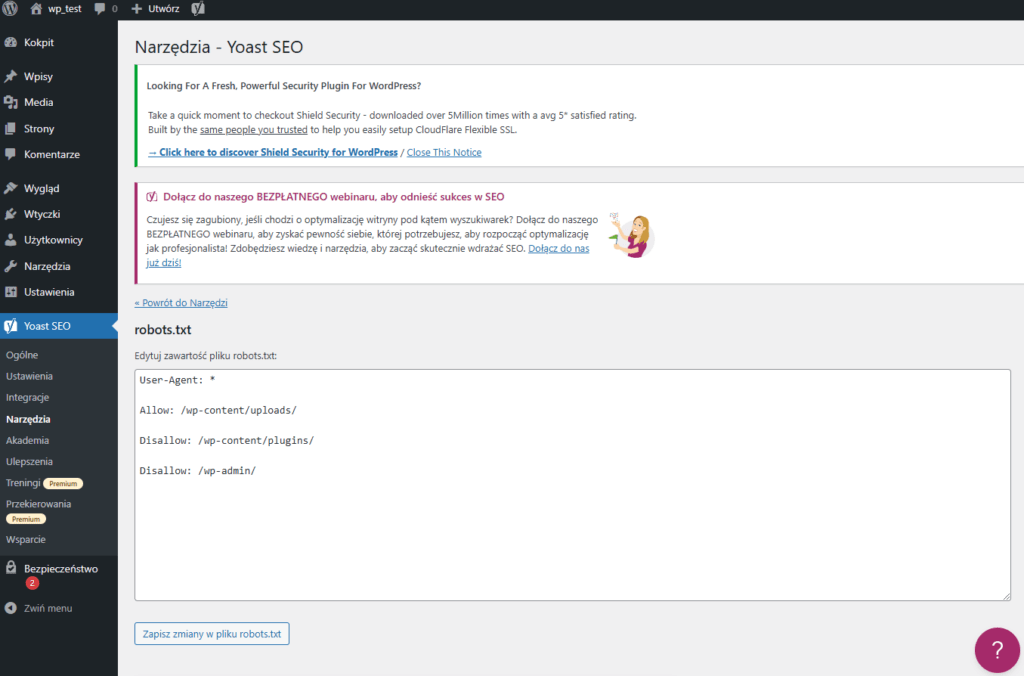
Na początek dodaj następujące reguły.
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Dodawanie reguł
Zasadniczo istnieją tylko dwie instrukcje, które możesz dać botom wyszukiwarek: Allow i Disallow. Allow przyznaje im dostęp do folderu, a Disallow robi odwrotnie.
Aby zezwolić na dostęp do folderu, dodaj:
User-Agent: * Allow: /wp-content/uploads/
Gwiazdka (*) informuje roboty wyszukiwarek: „Zasada dotyczy was wszystkich”.
Aby zablokować dostęp do folderu, użyj następującej reguły
Disallow: /wp-content/plugins/
W tym przypadku odmawiamy robotom wyszukiwawczym dostępu do folderu wtyczek.
Całkowicie od Ciebie zależy, która reguła jest najbardziej odpowiednia dla Twojej witryny. Jeśli na przykład prowadzisz forum, możesz zdecydować się na zablokowanie crawlerów na stronie forum za pomocą następującej reguły:
Disallow: /forum/
Jako reguła praktyczna, im mniej reguł, tym lepiej. Poniższa reguła wystarczy, aby wykonać zadanie:
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Disallow: /wp-admin/
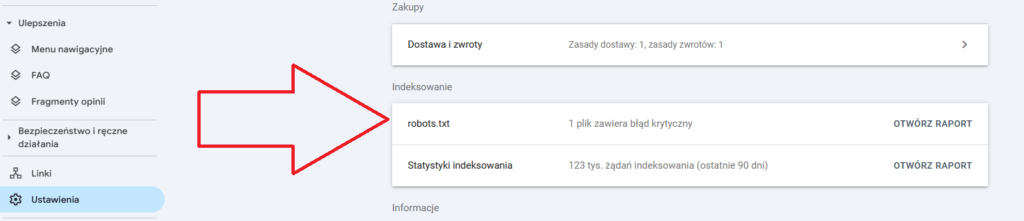
Jak przetestować utworzony plik Robots.txt w Google Search Console
Teraz, gdy utworzyłeś plik robots.txt w WordPressie, musisz się upewnić, że działa tak, jak powinien. I nie ma lepszego sposobu, aby to zrobić, niż użycie narzędzia testującego robots.txt.
Google Search Console ma odpowiednie narzędzie do tego celu. Więc po pierwsze, zaloguj się na swoje
konto Google Console . Zawsze możesz utworzyć konto, jeśli go nie masz.